In the previous post, I wrote about expectation, a great tool that helps us capture notion of “center” for a random variable. In this post, I will write about variance, another great tool that represents the “spread” of a random variable.
Consider a random variable  with two probability density functions (PDFs)
with two probability density functions (PDFs)  and
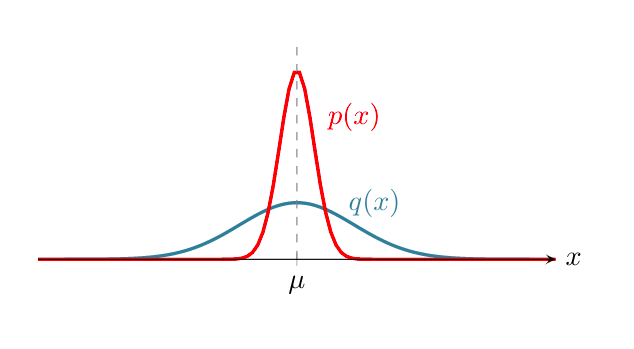
and  , shown in the figure below. under both PDFs has the same expected value (i.e.,
, shown in the figure below. under both PDFs has the same expected value (i.e., ![\mu = \E_{p(x)}[x] = \E_{q(x)}[x]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-aab71fe453fbdde06121cdbfb961734d_l3.png "Rendered by QuickLaTeX.com") ). But, has a larger “spread” compared to . In other words, samples drawn from deviate more from their mean than samples drawn from . Variance helps us represent this notion of spread from mean.
). But, has a larger “spread” compared to . In other words, samples drawn from deviate more from their mean than samples drawn from . Variance helps us represent this notion of spread from mean.
Definition:
The variance of a random variable is represented by  and is defined by the expected value of the squared deviation from the mean
and is defined by the expected value of the squared deviation from the mean ![\mu = \E[x]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-9b062c06349c6ecfa6b3a25a47475544_l3.png "Rendered by QuickLaTeX.com") :
:
![\[ \var{x} = \E[(x - \mu)^2]. \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-cc28319109a3ac51f85fec417e6f60d3_l3.png "Rendered by QuickLaTeX.com")
is also often represented by  as the variance is the square of the standard deviation denoted by
as the variance is the square of the standard deviation denoted by  .
.
The variance can also be expanded as:
![\begin{align*} \var{x} &= \E[(x - \mu)^2] \\ &= \E[x^2 - 2 \mu x + \mu^2 ] \\ &= \E[x^2] - 2\mu\E[x] + \mu^2 \\ &= \E[x^2] - 2\mu\mu + \mu^2 \\ &= \E[x^2] - \mu^2 \\ &= \E[x^2] - \E[x]^2. \end{align*}](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-a361c2da9ecba3084bfdcca178dcc0c2_l3.png "Rendered by QuickLaTeX.com")
Variance is closely related to covariance that represents the linear dependency between two variables. In fact, it is easy to see that:
![\[ \var{x} = \cov{x}{x} \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-4a2716d1e95b72f9611d304343ed309f_l3.png "Rendered by QuickLaTeX.com")
Properties:
Sign: Variance is always non-negative:
![\[ \var{x} \geq 0. \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-cac820ae30520086972fa456db5460d9_l3.png "Rendered by QuickLaTeX.com")
Shift invariance: Variance is invariant to shift:
![\[ \var{x + c} = \var{x}, \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-4dd6c329f2ebd3c4b472228ec463a5b9_l3.png "Rendered by QuickLaTeX.com")
where  is a constant.
is a constant.
Scaling: Scaling a random variable by , scales the variance by  :
:
(1) 
Sum: The variance of sum/minus is:

where  denotes the covariance between two random variables. This can be easily generalized to the sum of many random variables:
denotes the covariance between two random variables. This can be easily generalized to the sum of many random variables:
![\[ \var{\sum_i x_i} = \sum_i \var{x_i} + 2 \sum_{i \neq j} \cov{x_i}{x_j} \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-2db1a0f2d2fccf2abc49bc96d4935214_l3.png "Rendered by QuickLaTeX.com")
If all  are independent or uncorrelated, we have
are independent or uncorrelated, we have  ,
,  . This results in:
. This results in:
(2) 
Example:
Assume is a Normally-distributed random variable with mean  and variance , i.e.,
and variance , i.e.,  . We use a Monte Carlo estimate of the mean by drawing
. We use a Monte Carlo estimate of the mean by drawing  samples from the distribution denoted by
samples from the distribution denoted by  :
:
![\[ \hat{\mu} = \frac{1}{N} \sum_{n=1}^{N} x^{(n)} \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-ecf72491f0d271c797c9a2fd8bc61592_l3.png "Rendered by QuickLaTeX.com")
what are the mean and variance of  ?
?
First, we should note that itself is a random variable. In other words, it has its own distribution with its own mean and variance. Second, is a stochastic estimation of . i.e., is fixed in our problem, but depends on the set of samples . If we calculate using a different set of samples, its value will be different.
Mean: Let’s use what we learned in the previous post to derive the mean of :
![\begin{align*} \E[\hat{\mu}] &= \E[\frac{1}{N} \sum_{n=1}^{N} x^{(n)}] = \frac{1}{N} \sum_{n=1}^{N} \E[x^{(n)}] = \frac{1}{N} \sum_{n=1}^{N} \mu = \mu \end{align*}](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-71fd465f888f768f9921d03f00e45a6a_l3.png "Rendered by QuickLaTeX.com")
So, the expected value of is .
Variance: Since the set of samples are drawn independently, we can use the sum and scaling properties (Eq.1 and 2):

As you can see, the variance of depends on the sample size. As the sample size grows  goes to zero. In fact the sum of Normally-distributed random variables has a Normal distribution itself. Thus, we have
goes to zero. In fact the sum of Normally-distributed random variables has a Normal distribution itself. Thus, we have  . As increases, the distribution of which is centered at , becomes narrower, and as a result, approaches .
. As increases, the distribution of which is centered at , becomes narrower, and as a result, approaches .
Why variance is important in training:
Recall that in the previous post I mentioned that many training objective functions take the form of an expectation. The gradient of those objective functions is also in the form of an expectation. Since in general, we don’t have an analytic expression for the expected value of the gradient, we typically use a stochastic estimation of the gradient for optimizing the objective function. In this case, the variance of the gradient estimator plays a crucial role in training. High gradient variance can extremely slow down the training progress.
In practice, many factors impact the variance of a gradient estimator. Here, we are going to analyze the effect of the training batch size. Let’s consider a model with a single parameter. We represent this model by  where is an input instance and
where is an input instance and  is the parameter. For example, our model can be as simple as a linear function
is the parameter. For example, our model can be as simple as a linear function  . Let’s denote the target variable by
. Let’s denote the target variable by  and the loss function measuring the mismatch between the model output and target by
and the loss function measuring the mismatch between the model output and target by  . The training objective is to find that has the lowest loss in average. This is formulated as minimizing the following expectation:
. The training objective is to find that has the lowest loss in average. This is formulated as minimizing the following expectation:
![\[ \mathcal{L}(w) = \E_{p(x,y)}[l(f_w(x), y)], \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-b345b6cd9cd5db3e63be6a438327b5ff_l3.png "Rendered by QuickLaTeX.com")
where  is the joint distribution of input and target variables. We can use a gradient-based optimization method to minimize
is the joint distribution of input and target variables. We can use a gradient-based optimization method to minimize  . For this, we require computing the gradient of the loss function:
. For this, we require computing the gradient of the loss function:
![\[ \frac{\partial \mathcal{L}(w)}{\partial w} = \E_{p(x,y)}[\frac{\partial}{\partial w} l(f_w(x), y)] \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-5b598beb718b6dcb06418b260865f2f6_l3.png "Rendered by QuickLaTeX.com")
As you can see both the objective function and the gradient  are in the form of an expectation.
are in the form of an expectation.
We don’t have the joint explicitly. Thus, we cannot compute the expectations analytically. However, the training dataset  are samples drawn from the joint . We can define a Monte Carlo estimate of the gradient using a mini-batch of
are samples drawn from the joint . We can define a Monte Carlo estimate of the gradient using a mini-batch of  randomly-selected training datapoints:
randomly-selected training datapoints:
![\[ \hat{g} = \frac{1}{M}\sum_{i=1}^{M} \frac{\partial}{\partial w} l(f_w(x^{(i)}), y^{(i)}), \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-e745269ed73682ad71c05764294ee045_l3.png "Rendered by QuickLaTeX.com")
where  is the stochastic estimator of . As we saw in the example,
is the stochastic estimator of . As we saw in the example,  where
where  . We generally don’t have
. We generally don’t have  , so we cannot quantify
, so we cannot quantify  . However, it is easy to see that reduces as the mini-batch size increases. In other words, increasing the training mini-batch size, in average, brings closer to the true gradient.
. However, it is easy to see that reduces as the mini-batch size increases. In other words, increasing the training mini-batch size, in average, brings closer to the true gradient.
Summary
In this post, we learned about variance and its basic properties, and we saw how we can use them to derive the mean and variance of an estimator. In the next post, we will dig deeper into an ML problem to better understand how these fundamental concepts play together during training. If you like to stay updated with the future posts, you can use the form below to subscribe.