Machine learning (ML) is filled with various forms of mathematical expectations. It is not exaggerated to say that almost all training objective functions in ML are in the form of an expectation. In this blog post, I will review some basics on expectations to create a foundation for my next posts on probabilistic ML.
I personally believe that everyone should learn to use expectations for making personal decisions. Estimating the expected value of an outcome and the variance associated with it is typically used for analyzing investment opportunities by professional investors.
Simple Example:
Imagine you want to buy a lottery ticket for $2 and you would like to know what you will win on average. You know 1 million tickets are sold as part of this lottery and the prizes are:
- $1M for 1 person
- $10,000 for 10 people
- $1,000 for 100 people
- $100 for 1,000 people
Let’s look at the probability of each event:
- You win $1M with probability 1 in one million

- You win $10K with probability 1 in 100,000

- You win $1K with probability 1 in 10,000

- You win $100 with probability 1 in 1,000

- You win nothing with probability

Let’s represent each of these events using  . We know for example
. We know for example  . Let’s also represent the prize you win with
. Let’s also represent the prize you win with  , i.e.,
, i.e.,  $1M if
$1M if  . The expected value of the prize you will win is:
. The expected value of the prize you will win is:
![\[ \mathbb{E}_{x\sim p(x)}[f(x)] = \sum_{x \in \mathcal{X}} p(x) f(x). \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-f894f0388bda66940e77803b9e259e97_l3.png "Rendered by QuickLaTeX.com")
You can think of this equation as averaging the values of an outcome with weights equal to the probability of that outcome. So, rare outcomes are weighted with smaller weights. The expected value of the prize is:
![\[ 10^{-6} \times 10^6 + 10^{-5} \times 10^4 +10^{-4} \times 10^3 + 10^{-3} \times 100 + 0 \times 0.999 = \$1.3 \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-17c1de2d98ea586f5fe703bb4897340a_l3.png "Rendered by QuickLaTeX.com")
So on average, you will win $1.3 by paying $2!
What amazes me here is that the number $1.3 cannot be seen easily in the list of the prizes. By looking at this list you may think that “at least you will win $100 which is 50 times what you invested ($2)”.
Definition:
If  is a discrete random variable with
is a discrete random variable with  representing the set of all possible values of
representing the set of all possible values of  , the expected value of given that has distribution
, the expected value of given that has distribution  is denoted by:
is denoted by:
Sometimes this notation is simplified to ![\mathbb{E}_{p(x)}[f(x)]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-865ca35b6c882720ad4e05e919f6ba93_l3.png "Rendered by QuickLaTeX.com") or even
or even ![\mathbb{E}[f(x)]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-5f8e6aaeb47d83408476ef3b2a333b18_l3.png "Rendered by QuickLaTeX.com") if the distribution of is implied.
if the distribution of is implied.
If  is a continuous random variable where
is a continuous random variable where  is the sample space of , the summation is replaced by an integral:
is the sample space of , the summation is replaced by an integral:
![\[ \mathbb{E}_{x\sim p(x)}[f(x)] = \int_\Omega p(x) f(x) dx. \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-6a307832096f45d0b3132c5ec51d3f0c_l3.png "Rendered by QuickLaTeX.com")
Here, is the probability density function for random variable . For example if has a Normal distribution, its sample space is the space of all real numbers  . In this case the integral is written as:
. In this case the integral is written as:
![\[ \mathbb{E}_{x\sim p(x)}[f(x)] = \int_{-\infty}^{+\infty} p(x) f(x) dx. \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-e219c6f8cc8f29ff5aecc638c652b942_l3.png "Rendered by QuickLaTeX.com")
Properties:
Let’s go over some of the properties that are commonly used in ML:
1) Mean: If  , then is the mean of the random variable .
, then is the mean of the random variable .
2) Constant: If  is constant, i.e.,
is constant, i.e.,  , the expected value is also constant:
, the expected value is also constant:
![\[ \mathbb{E}_{p(x)}[c] = \int p(x)\,c\,dx = c\int p(x)\,dx=c. \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-38d834f05d45c1df8377b2b3ee243773_l3.png "Rendered by QuickLaTeX.com")
3) Linearity:
![\begin{align*} \mathbb{E}_{p(x)}[af(x)] &= a\mathbb{E}_{p(x)}[f(x)] \\ \mathbb{E}_{p(x, y)}[f(x)+g(y)] &= \mathbb{E}_{p(x)}[f(x)] + \mathbb{E}_{p(y)}[g(y)] \end{align*}](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-34969491b24d2a989117f783e17490f1_l3.png "Rendered by QuickLaTeX.com")
where and  are two random variables.
are two random variables.
4) Jensen’s inequality: If is a convex function, we have:
![\[ f(\mathbb{E}_{p(x)}[x]) \leq \mathbb{E}_{p(x)}[f(x)] \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-d39f8dfe363cca16578da04a48c7faf2_l3.png "Rendered by QuickLaTeX.com")
In other words, if you apply a convex function to the expected value of a random variable, it will be less than or equal to the expected value of the function. The direction of the inequality changes if is a concave function. I will discuss this inequality in more details in another post.
Computing an Expectation:
In many ML problems, we are often required to compute the value of an expectation. Here, I review three different approaches to tackle this problem. For this section, let’s assume we are interested in finding the expected value of a Normal random variable with mean  and standard deviation
and standard deviation  . That is to say find:
. That is to say find:
![\[ \mathbb{E}_{p(x)}[x] = \int_{-\infty}^{+\infty}p(x)xdx, \ \ \text{where} \ \ p(x)=\mathcal{N}(x;\mu, \sigma). \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-99522485e98054bbe680dad045b5e48d_l3.png "Rendered by QuickLaTeX.com")
1) Know your functions:
Solving an expectation is the same as taking the integral of a function. This function is nothing but the product of the probability density function and . In our example, the functions  and
and  look like:
look like:
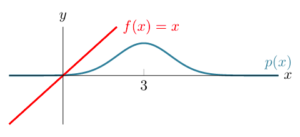
Above, it is not clear how we can take the integral of  . But, if was shifted such that it was crossing the -axis at the mean of the Normal distribution, we would have symmetric functions. This shifted function is
. But, if was shifted such that it was crossing the -axis at the mean of the Normal distribution, we would have symmetric functions. This shifted function is  :
:
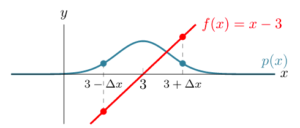
As you can see above both and  are symmetric around
are symmetric around  (the mean of the Normal distribution). The symmetry is such that if we consider two mirrored points
(the mean of the Normal distribution). The symmetry is such that if we consider two mirrored points  and
and  , the probability density function is equal, i.e.,
, the probability density function is equal, i.e.,  for any positive
for any positive  . But, the function is negated for those points, i.e.,
. But, the function is negated for those points, i.e.,  . As you can guess, the product of and
. As you can guess, the product of and  is also symmetric:
is also symmetric:
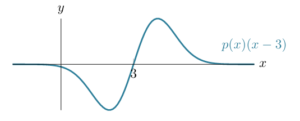
Given this symmetry, it is easy to see that the integral of  for the entire -axis is zero. This means
for the entire -axis is zero. This means ![\mathbb{E}_{p(x)}[x - 3] = 0](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-219506a601bee8013e15413175bdcb01_l3.png "Rendered by QuickLaTeX.com") . Now, we can use this to solve our expectation problem:
. Now, we can use this to solve our expectation problem:
![\[ \mathbb{E}_{p(x)}[x] = \mathbb{E}_{p(x)}[x-3+3] = \mathbb{E}_{p(x)}[x-3] + \mathbb{E}_{p(x)}[3] = 0 + 3 = 3 \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-86e71da088aef28d1fc42d7b06dcb226_l3.png "Rendered by QuickLaTeX.com")
2) Just do the math:
So far, we have used the shape of the functions and to derive the expected value. In practice, visualizing a function and underlying distribution does not always result in the value of an expectation, but it gives us intuitions on how to attack the problem. Here, we will try to solve the integral directly using techniques from calculus. We have:
![\begin{align*} \mathbb{E}_{p(x)}[x] &= \mathbb{E}_{p(x)}[x - 3 + 3] = \mathbb{E}_{p(x)}[x-3] + \mathbb{E}_{p(x)}[3] \\ &= \int_{-\infty}^{+\infty}\frac{1}{\sqrt{2\pi}}e^{-\frac{(x-3)^2}{2}}(x-3)dx + 3 \end{align*}](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-c9dd276614f1374eac9dd8674a6387c1_l3.png "Rendered by QuickLaTeX.com")
Note that here we use the definition of Normal distribution, i.e.,  . Now, we can introduce the change of variable
. Now, we can introduce the change of variable  and
and  :
:
![\begin{align*} \mathbb{E}_{p(x)}[x] &= \int_{+\infty}^{+\infty}\frac{1}{\sqrt{2\pi}}e^{-u}du + 3 \\ &= - \frac{1}{\sqrt{2\pi}} e^{-u} \big]_{+\infty}^{+\infty} + 3 = 0 + 3 = 3 \end{align*}](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-faa6460d0126695205b6c743ebce9a89_l3.png "Rendered by QuickLaTeX.com")
3) Draw Samples:
The most general approach for solving an expectation is to use a sampling-based method called the Monte Carlo method. This approach can be used only if we can draw samples from distribution . Let’s represent a set of  samples from by
samples from by  . Based on the Monte Carlo method, we have:
. Based on the Monte Carlo method, we have:
![\[ \mathbb{E}_{p(x)}[x] \approx \frac{1}{L} \sum_{l=1}^{L} x^{(l)}, \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-a496c43c6a64981b576e6e5f53bf3619_l3.png "Rendered by QuickLaTeX.com")
which is to say that the expected value is approximated by taking the average of samples drawn from the distribution. For example, let’s draw 10 samples from  :
:
![\[ \{2.71, 4.45, 4.20, 3.12, 2.73, 1.17, 3.08, 0.56, 2.82, 2.94 \} \]](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-c7f0eca2b290b641381edb0539e5210b_l3.png "Rendered by QuickLaTeX.com")
If we take the average of these 10 samples, we will have ![\mathbb{E}_{p(x)}[x] \approx 2.78.](http://latentspace.cc/wp-content/ql-cache/quicklatex.com-9d33571c7d9470daf5ecd528c2089fe9_l3.png "Rendered by QuickLaTeX.com") Note that this estimate is not exactly the same as the estimate we get with the previous approaches. This is because the Monte Carlo method provides a stochastic estimation of the integral. This estimation is unbiased meaning that on average it is always equal to the true value. However, it contains variance (i.e., deviation from the true value). We will discuss this in more details later.
Note that this estimate is not exactly the same as the estimate we get with the previous approaches. This is because the Monte Carlo method provides a stochastic estimation of the integral. This estimation is unbiased meaning that on average it is always equal to the true value. However, it contains variance (i.e., deviation from the true value). We will discuss this in more details later.
Summary
In this post, I reviewed some basic properties of expectations and a few simple techniques for computing them. Among these techniques, the Monte Carlo method is widely used in ML especially if there is no closed-form derivation for an expectation. However, I typically find visualizing functions and distributions very informative, although it may not yield to a solution directly.
As you may know, I am just about to start this blog, and I need your help to reach out to a greater audience. So, if you like this post, please don’t hesitate to share it with your network. If you have any suggestion, please post it in the comments section.
I like the clarity and pace of your writing. Tnx
Keep it up please
Thank you!
Very clear explanation, please keep it up!
very good blog post
Thanks for sharing this. Very easy to follow and well written. I am looking forward for the next post.